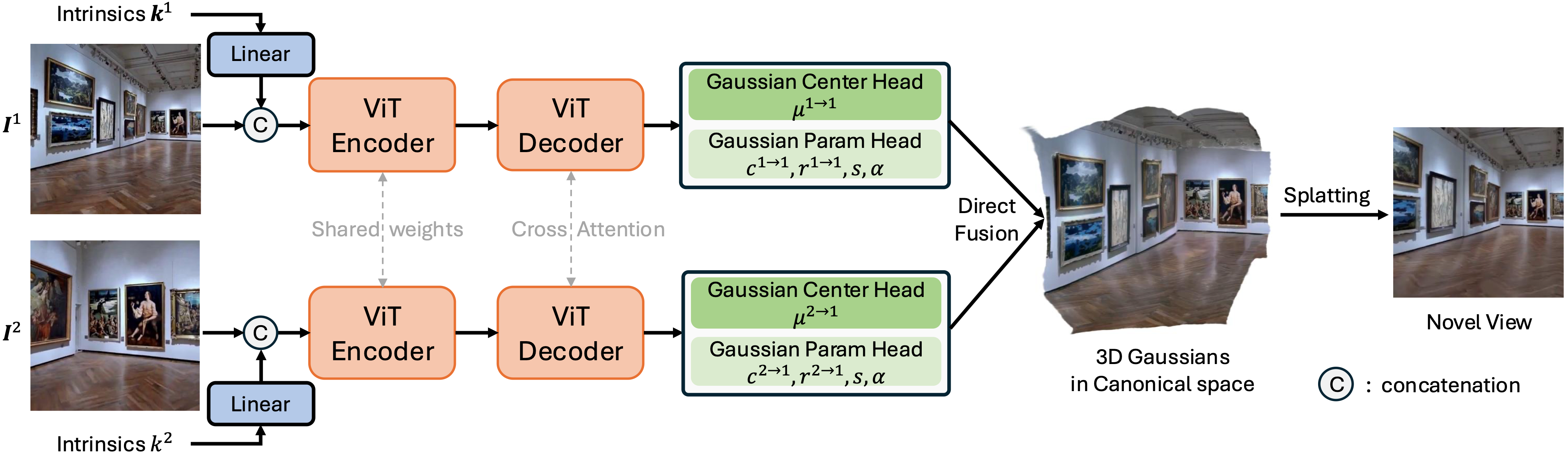
Overall Framework of NoPoSplat. Given sparse unposed images, our method directly reconstruct Gaussians in a canonical space from a feed-forward network to represent the underlying 3D scene. We also introduce a camera intrinsic token embedding, which is concatenated with the image tokens as input to the network to address the scale ambiguity problem. For simplicity, we use a two-view setup as an example.
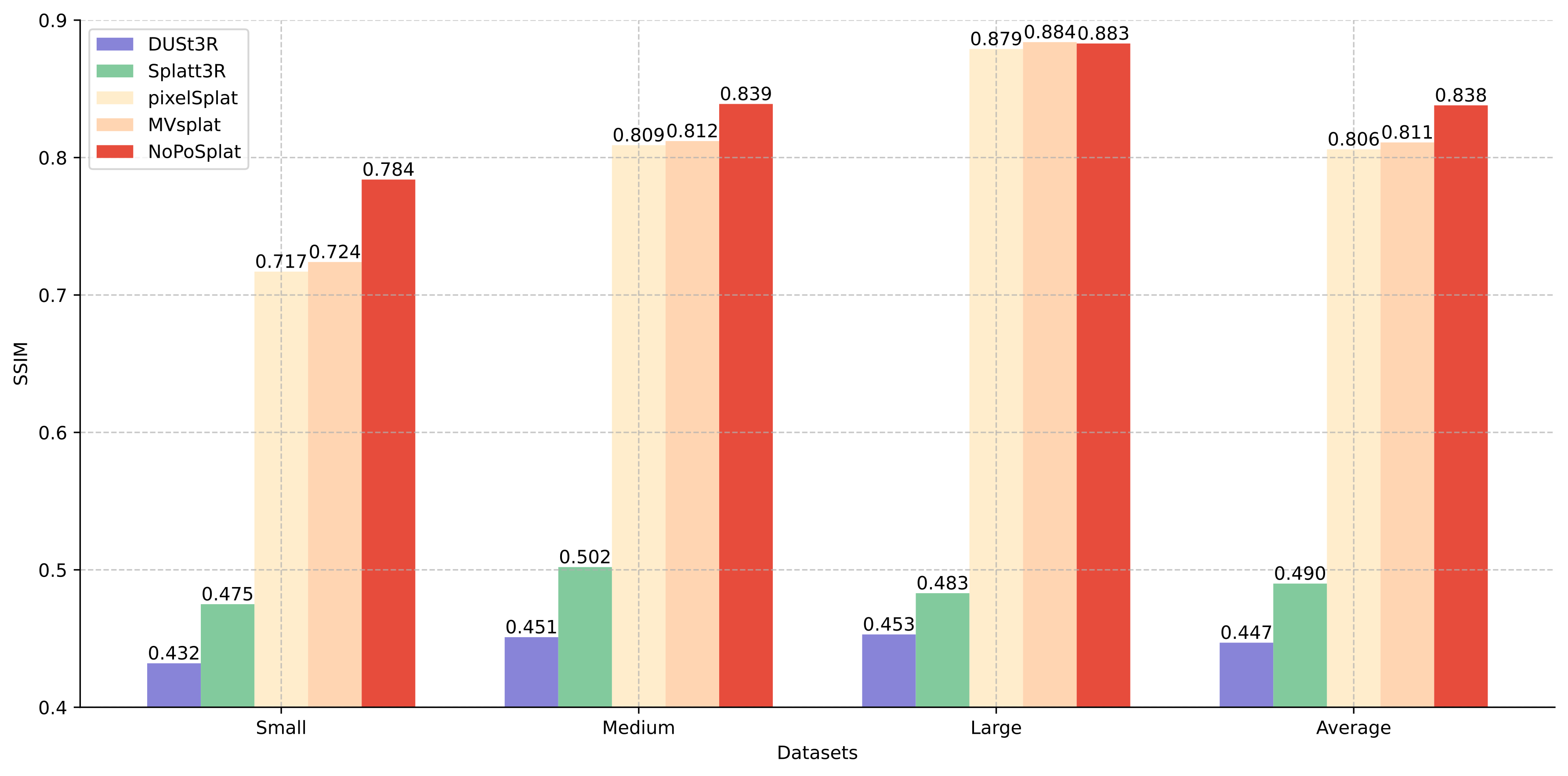
Novel view synthesis performance comparison on the RealEstate10k dataset.
Our method largely outperforms previous pose-free methods (DUSt3R and Splatt3R) on all overlap settings, and even outperforms SOTA pose-required methods (pixelSplat and MVSplat), especially when the overlap is small.
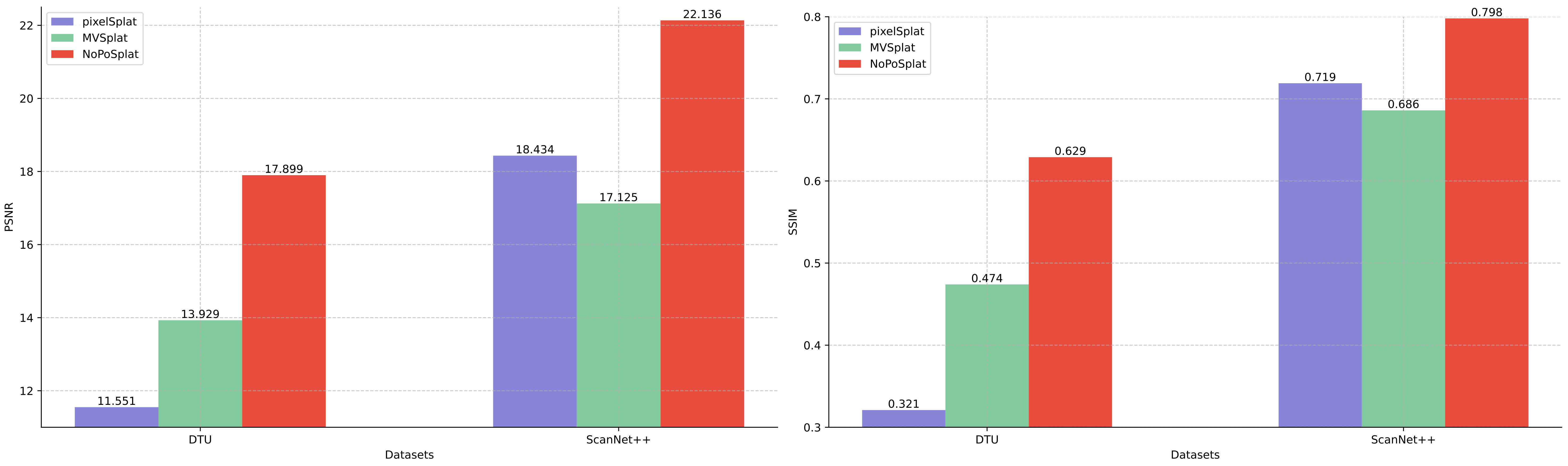
Out-of-distribution performance comparison.
Our method shows superior performance when zero-shot evaluation on DTU and ScanNet++ using the model solely trained on RE10k and generalize to DTU and ScanNet++.
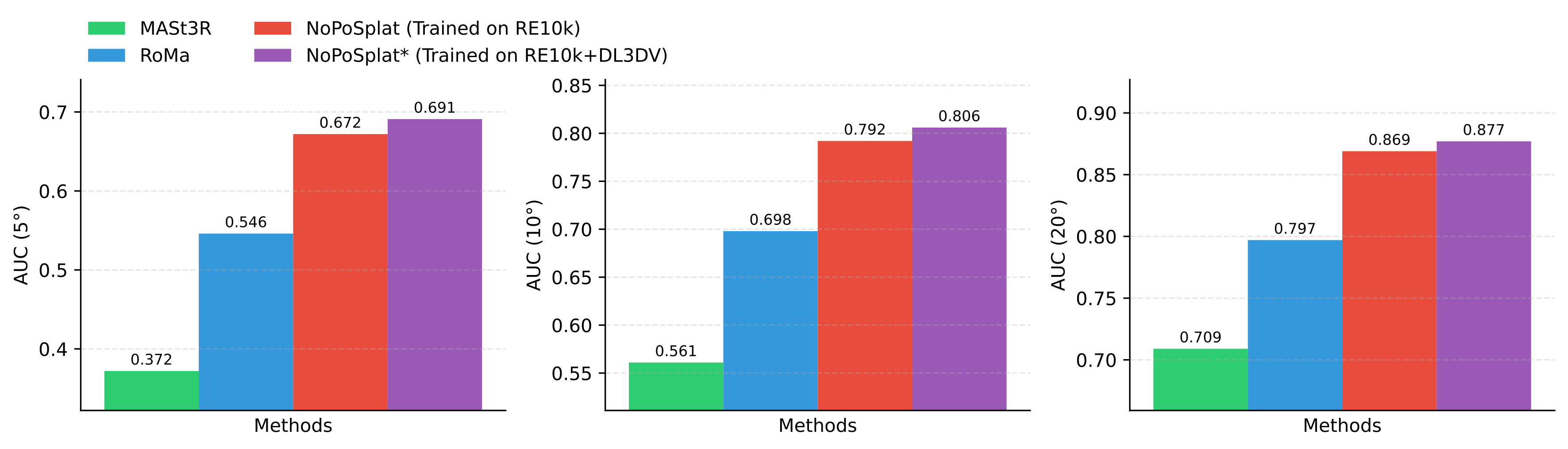
Pose Estimation performance comparison on the RealEstate10k dataset.
NoPoSplat largely outperforms previous SOTA pose estimation methods.
NoPoSplat does not require an explicit matching loss during training,
eliminating the need for ground truth depth and allowing it to be trained on video datasets such as RE10K.
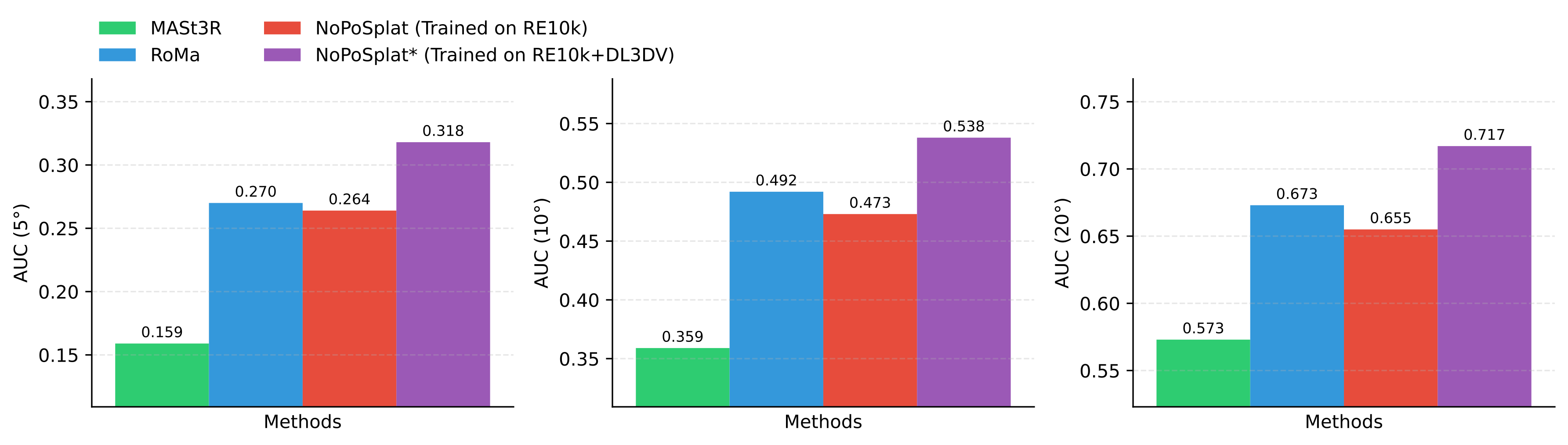
Pose Estimation performance comparison on the ACID dataset.
None of the methods are trained on this dataset, NoPoSplat achieves the best performance.
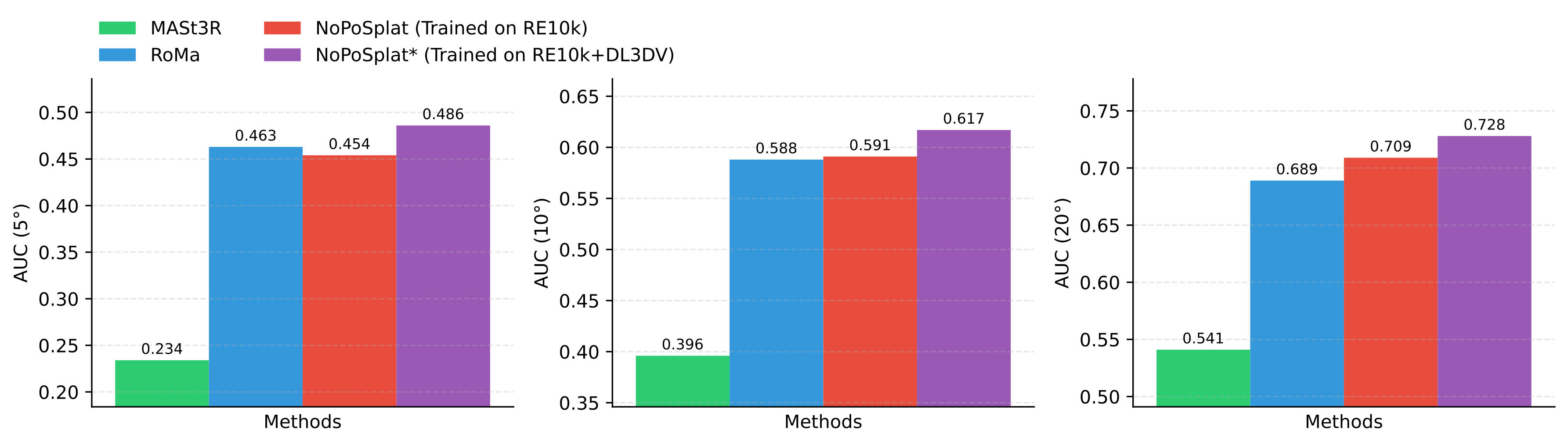
Pose Estimation performance comparison on the ScanNet-1500 dataset.
NoPoSplat is not trained on this dataset, but still achieves the best performance.
The red and green indicate input and target camera views, and the rendered image and depths are shown on the right side. The magenta and blue arrows correspond to the distorted or misalignment regions in baseline 3DGS. The results show that even without camera poses as input, our method produces higher-quality 3D Gaussians resulting in better color/depth rendering over baselines.

Compared to baselines, we obtain: 1) more coherent fusion from input views, 2) superior reconstruction from limited image overlap, 3) enhanced geometry reconstruction in non-overlapping regions.

Our model can better zero-shot transfer to out-of-distribution data than SOTA pose-required methods. MVSplat and pixelSplat struggle to smoothly merge the underlying geometry and appearance of different input views, whereas our NoPoSplat renders competitive and holistic novel views due to the design that outputs Gaussians in a canonical coordinate system
@article{ye2024noposplat,
title = {No Pose, No Problem: Surprisingly Simple 3D Gaussian Splats from Sparse Unposed Images},
author = {Ye, Botao and Liu, Sifei and Xu, Haofei and Xueting, Li and Pollefeys, Marc and Yang, Ming-Hsuan and Songyou, Peng},
journal = {arXiv preprint arXiv:2410.24207},
year = {2024}
}







